
1 TensorRT直接导出engine加速
TensorRT是nvidia家的一款高性能深度学习推理SDK。此SDK包含深度学习推理优化器和运行环境,可为深度学习推理应用提供低延迟和高吞吐量。在推理过程中,基于TensorRT的应用程序比仅仅使用CPU作为平台的应用程序要快40倍。
从应用上来说就是将原始yolov5采用的网络参数进行优化,提高计算与识别的实时性,首先下载源码:
注意需要下载V5.0的版本,cd进入其中的tensorrtx/yolov5地址建立编译空间:
mkdir build
cd build在yolov5目录中python脚本gen_wts.py完成对权重系数的转换,为了计算速度这里需要选择YoloV5,5.0版本对应的YoloV5n(5.0版本不支持5n):
https://gitcode.net/mirrors/wang-xinyu/tensorrtx/-/tree/yolov5-v5.0
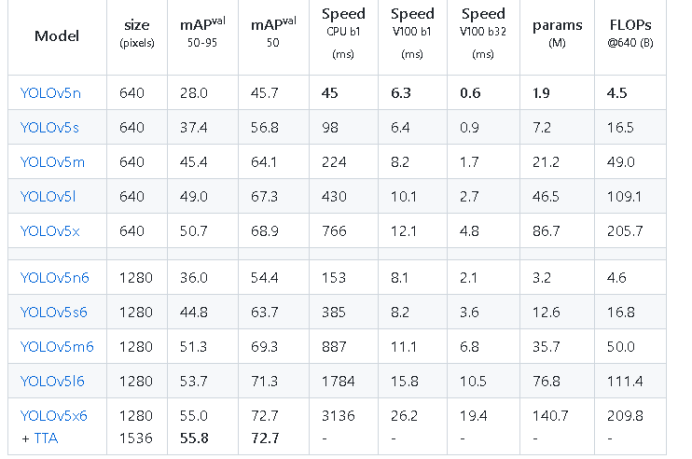
python gen_wts.py -w yolov5s.pt -o yolov5s.wts然后修改文件夹下的yololayer.h配置需要的网络输入与输入,对于实时性需求,我们可以减小INPUT_H ,INPUT_W为320*320提高计算速度:
#ifndef _YOLO_LAYER_H
#define _YOLO_LAYER_H
#include <vector>
#include <string>
#include <NvInfer.h>
#include "macros.h"
namespace Yolo
{
static constexpr int CHECK_COUNT = 3;
static constexpr float IGNORE_THRESH = 0.25f;
struct YoloKernel
{
int width;
int height;
float anchors[CHECK_COUNT * 2];
};
static constexpr int MAX_OUTPUT_BBOX_COUNT = 10;
static constexpr int CLASS_NUM = 80;
static constexpr int INPUT_H = 320; // yolov5's input height and width must be divisible by 32.
static constexpr int INPUT_W = 320;
static constexpr int LOCATIONS = 4;
struct alignas(float) Detection {
//center_x center_y w h
float bbox[LOCATIONS];
float conf; // bbox_conf * cls_conf
float class_id;
};
}
namespace nvinfer1
{
class API YoloLayerPlugin : public IPluginV2IOExt
{
public:
YoloLayerPlugin(int classCount, int netWidth, int netHeight, int maxOut, const std::vector<Yolo::YoloKernel>& vYoloKernel);
YoloLayerPlugin(const void* data, size_t length);
~YoloLayerPlugin();
int getNbOutputs() const TRT_NOEXCEPT override
{
return 1;
}
Dims getOutputDimensions(int index, const Dims* inputs, int nbInputDims) TRT_NOEXCEPT override;
int initialize() TRT_NOEXCEPT override;
virtual void terminate() TRT_NOEXCEPT override {};
virtual size_t getWorkspaceSize(int maxBatchSize) const TRT_NOEXCEPT override { return 0; }
virtual int enqueue(int batchSize, const void* const* inputs, void*TRT_CONST_ENQUEUE* outputs, void* workspace, cudaStream_t stream) TRT_NOEXCEPT override;
virtual size_t getSerializationSize() const TRT_NOEXCEPT override;
virtual void serialize(void* buffer) const TRT_NOEXCEPT override;
bool supportsFormatCombination(int pos, const PluginTensorDesc* inOut, int nbInputs, int nbOutputs) const TRT_NOEXCEPT override {
return inOut[pos].format == TensorFormat::kLINEAR && inOut[pos].type == DataType::kFLOAT;
}
const char* getPluginType() const TRT_NOEXCEPT override;
const char* getPluginVersion() const TRT_NOEXCEPT override;
void destroy() TRT_NOEXCEPT override;
IPluginV2IOExt* clone() const TRT_NOEXCEPT override;
void setPluginNamespace(const char* pluginNamespace) TRT_NOEXCEPT override;
const char* getPluginNamespace() const TRT_NOEXCEPT override;
DataType getOutputDataType(int index, const nvinfer1::DataType* inputTypes, int nbInputs) const TRT_NOEXCEPT override;
bool isOutputBroadcastAcrossBatch(int outputIndex, const bool* inputIsBroadcasted, int nbInputs) const TRT_NOEXCEPT override;
bool canBroadcastInputAcrossBatch(int inputIndex) const TRT_NOEXCEPT override;
void attachToContext(
cudnnContext* cudnnContext, cublasContext* cublasContext, IGpuAllocator* gpuAllocator) TRT_NOEXCEPT override;
void configurePlugin(const PluginTensorDesc* in, int nbInput, const PluginTensorDesc* out, int nbOutput) TRT_NOEXCEPT override;
void detachFromContext() TRT_NOEXCEPT override;
private:
void forwardGpu(const float* const* inputs, float *output, cudaStream_t stream, int batchSize = 1);
int mThreadCount = 256;
const char* mPluginNamespace;
int mKernelCount;
int mClassCount;
int mYoloV5NetWidth;
int mYoloV5NetHeight;
int mMaxOutObject;
std::vector<Yolo::YoloKernel> mYoloKernel;
void** mAnchor;
};
class API YoloPluginCreator : public IPluginCreator
{
public:
YoloPluginCreator();
~YoloPluginCreator() override = default;
const char* getPluginName() const TRT_NOEXCEPT override;
const char* getPluginVersion() const TRT_NOEXCEPT override;
const PluginFieldCollection* getFieldNames() TRT_NOEXCEPT override;
IPluginV2IOExt* createPlugin(const char* name, const PluginFieldCollection* fc) TRT_NOEXCEPT override;
IPluginV2IOExt* deserializePlugin(const char* name, const void* serialData, size_t serialLength) TRT_NOEXCEPT override;
void setPluginNamespace(const char* libNamespace) TRT_NOEXCEPT override
{
mNamespace = libNamespace;
}
const char* getPluginNamespace() const TRT_NOEXCEPT override
{
return mNamespace.c_str();
}
private:
std::string mNamespace;
static PluginFieldCollection mFC;
static std::vector<PluginField> mPluginAttributes;
};
REGISTER_TENSORRT_PLUGIN(YoloPluginCreator);
};
#endif // _YOLO_LAYER_H之后将得到的.wts文件拷贝到build目录下编译转换器:
cmake ..
make然后使用得到的文件转换为engine:
./yolov5 -s yolov5s.wts yolov5s.engine s## Below content will show if program success Loading weights: best.wts
Building engine, please wait for a while...
Build engine successfully!
Building engine, please wait for a while...
Build engine successfully!
参考资料:
常见错误:
由于JetsonNano显存很小,如果启动YoloV5和Rviz可能导致死机,我们建议用PC启动Rviz显示,并在使用时关闭远程桌面,下面关闭图像的操作仅供参考:
如果需要关闭JetsonNano图形界面加快识别可以使用,但是并不建议,容易造成开机黑屏:
sudo systemctl set-default graphical.target
重启后重新打开:
sudo systemctl set-default graphical.target
sudo systemctl set-default graphical.target
重启后重新打开:
sudo systemctl set-default graphical.target
安装无误后进行测试,启动程序可以看到识别帧率达到20帧左右:
roslaunch robot_vslam camera.launch
roslaunch yolov5_ros yolo_v5f.launch
roslaunch robot_navigation multi_navigation.launch可以看到通过tensorrtx加速相比原始版本可以达到基本实时的状态,但是当目标数量较多时其识别的帧率也会下降!

识别结果,5.0版本识别精度不高,有需要可以安装高版本,但是如果更新python ROS相关包都需要重新安装,容易造成镜像损坏
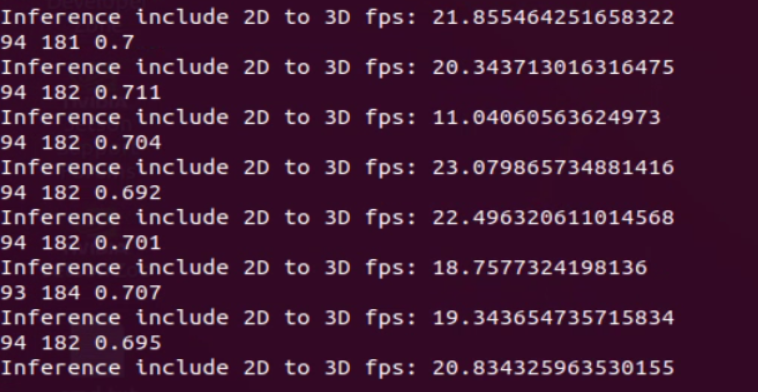
速度文档在20帧左右
2 通过ONNX加速
除了采用TensorRT直接导出engine加速外,还可以先将pt参数先转换为通用onnx格式,然后调研简化器,之后再将简化后的onnx转换会engine,具体流程如下:
安装依赖:
sudo apt-get install protobuf-compiler libprotoc-dev
pip3 install onnx==1.11.0将yolo5原始参数转换为onnx:
python3 ./export.py --weights ./yolov5s.pt --img 640 --batch 1 --include=onnx
如果没有该export文件可以新建如下py脚本:
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
"""
Export a YOLOv5 PyTorch model to other formats. TensorFlow exports authored by https://github.com/zldrobit
Format | `export.py --include` | Model
--- | --- | ---
PyTorch | - | yolov5s.pt
TorchScript | `torchscript` | yolov5s.torchscript
ONNX | `onnx` | yolov5s.onnx
OpenVINO | `openvino` | yolov5s_openvino_model/
TensorRT | `engine` | yolov5s.engine
CoreML | `coreml` | yolov5s.mlmodel
TensorFlow SavedModel | `saved_model` | yolov5s_saved_model/
TensorFlow GraphDef | `pb` | yolov5s.pb
TensorFlow Lite | `tflite` | yolov5s.tflite
TensorFlow Edge TPU | `edgetpu` | yolov5s_edgetpu.tflite
TensorFlow.js | `tfjs` | yolov5s_web_model/
Usage:
$ python path/to/export.py --weights yolov5s.pt --include torchscript onnx openvino engine coreml tflite ...
Inference:
$ python path/to/detect.py --weights yolov5s.pt # PyTorch
yolov5s.torchscript # TorchScript
yolov5s.onnx # ONNX Runtime or OpenCV DNN with --dnn
yolov5s.xml # OpenVINO
yolov5s.engine # TensorRT
yolov5s.mlmodel # CoreML (MacOS-only)
yolov5s_saved_model # TensorFlow SavedModel
yolov5s.pb # TensorFlow GraphDef
yolov5s.tflite # TensorFlow Lite
yolov5s_edgetpu.tflite # TensorFlow Edge TPU
TensorFlow.js:
$ cd .. && git clone https://github.com/zldrobit/tfjs-yolov5-example.git && cd tfjs-yolov5-example
$ npm install
$ ln -s ../../yolov5/yolov5s_web_model public/yolov5s_web_model
$ npm start
"""
import argparse
import json
import os
import platform
import subprocess
import sys
import time
from pathlib import Path
import torch
import torch.nn as nn
from torch.utils.mobile_optimizer import optimize_for_mobile
FILE = Path(__file__).resolve()
ROOT = FILE.parents[0] # YOLOv5 root directory
if str(ROOT) not in sys.path:
sys.path.append(str(ROOT)) # add ROOT to PATH
ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
from models.common import Conv
from models.experimental import attempt_load
from models.yolo import Detect
from utils.activations import SiLU
from utils.datasets import LoadImages
from utils.general import (LOGGER, check_dataset, check_img_size, check_requirements, check_version, colorstr,
file_size, print_args, url2file)
from utils.torch_utils import select_device
def export_torchscript(model, im, file, optimize, prefix=colorstr('TorchScript:')):
# YOLOv5 TorchScript model export
try:
LOGGER.info(f'\n{prefix} starting export with torch {torch.__version__}...')
f = file.with_suffix('.torchscript')
ts = torch.jit.trace(model, im, strict=False)
d = {"shape": im.shape, "stride": int(max(model.stride)), "names": model.names}
extra_files = {'config.txt': json.dumps(d)} # torch._C.ExtraFilesMap()
if optimize: # https://pytorch.org/tutorials/recipes/mobile_interpreter.html
optimize_for_mobile(ts)._save_for_lite_interpreter(str(f), _extra_files=extra_files)
else:
ts.save(str(f), _extra_files=extra_files)
LOGGER.info(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
return f
except Exception as e:
LOGGER.info(f'{prefix} export failure: {e}')
def export_onnx(model, im, file, opset, train, dynamic, simplify, prefix=colorstr('ONNX:')):
# YOLOv5 ONNX export
try:
check_requirements(('onnx',))
import onnx
LOGGER.info(f'\n{prefix} starting export with onnx {onnx.__version__}...')
f = file.with_suffix('.onnx')
torch.onnx.export(model, im, f, verbose=False, opset_version=opset,
training=torch.onnx.TrainingMode.TRAINING if train else torch.onnx.TrainingMode.EVAL,
do_constant_folding=not train,
input_names=['images'],
output_names=['output'],
dynamic_axes={'images': {0: 'batch', 2: 'height', 3: 'width'}, # shape(1,3,640,640)
'output': {0: 'batch', 1: 'anchors'} # shape(1,25200,85)
} if dynamic else None)
# Checks
model_onnx = onnx.load(f) # load onnx model
onnx.checker.check_model(model_onnx) # check onnx model
# LOGGER.info(onnx.helper.printable_graph(model_onnx.graph)) # print
# Simplify
if simplify:
try:
check_requirements(('onnx-simplifier',))
import onnxsim
LOGGER.info(f'{prefix} simplifying with onnx-simplifier {onnxsim.__version__}...')
model_onnx, check = onnxsim.simplify(
model_onnx,
dynamic_input_shape=dynamic,
input_shapes={'images': list(im.shape)} if dynamic else None)
assert check, 'assert check failed'
onnx.save(model_onnx, f)
except Exception as e:
LOGGER.info(f'{prefix} simplifier failure: {e}')
LOGGER.info(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
return f
except Exception as e:
LOGGER.info(f'{prefix} export failure: {e}')
def export_openvino(model, im, file, prefix=colorstr('OpenVINO:')):
# YOLOv5 OpenVINO export
try:
check_requirements(('openvino-dev',)) # requires openvino-dev: https://pypi.org/project/openvino-dev/
import openvino.inference_engine as ie
LOGGER.info(f'\n{prefix} starting export with openvino {ie.__version__}...')
f = str(file).replace('.pt', '_openvino_model' + os.sep)
cmd = f"mo --input_model {file.with_suffix('.onnx')} --output_dir {f}"
subprocess.check_output(cmd, shell=True)
LOGGER.info(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
return f
except Exception as e:
LOGGER.info(f'\n{prefix} export failure: {e}')
def export_coreml(model, im, file, prefix=colorstr('CoreML:')):
# YOLOv5 CoreML export
try:
check_requirements(('coremltools',))
import coremltools as ct
LOGGER.info(f'\n{prefix} starting export with coremltools {ct.__version__}...')
f = file.with_suffix('.mlmodel')
ts = torch.jit.trace(model, im, strict=False) # TorchScript model
ct_model = ct.convert(ts, inputs=[ct.ImageType('image', shape=im.shape, scale=1 / 255, bias=[0, 0, 0])])
ct_model.save(f)
LOGGER.info(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
return ct_model, f
except Exception as e:
LOGGER.info(f'\n{prefix} export failure: {e}')
return None, None
def export_engine(model, im, file, train, half, simplify, workspace=4, verbose=False, prefix=colorstr('TensorRT:')):
# YOLOv5 TensorRT export https://developer.nvidia.com/tensorrt
try:
check_requirements(('tensorrt',))
import tensorrt as trt
if trt.__version__[0] == '7': # TensorRT 7 handling https://github.com/ultralytics/yolov5/issues/6012
grid = model.model[-1].anchor_grid
model.model[-1].anchor_grid = [a[..., :1, :1, :] for a in grid]
export_onnx(model, im, file, 12, train, False, simplify) # opset 12
model.model[-1].anchor_grid = grid
else: # TensorRT >= 8
check_version(trt.__version__, '8.0.0', hard=True) # require tensorrt>=8.0.0
export_onnx(model, im, file, 13, train, False, simplify) # opset 13
onnx = file.with_suffix('.onnx')
LOGGER.info(f'\n{prefix} starting export with TensorRT {trt.__version__}...')
assert im.device.type != 'cpu', 'export running on CPU but must be on GPU, i.e. `python export.py --device 0`'
assert onnx.exists(), f'failed to export ONNX file: {onnx}'
f = file.with_suffix('.engine') # TensorRT engine file
logger = trt.Logger(trt.Logger.INFO)
if verbose:
logger.min_severity = trt.Logger.Severity.VERBOSE
builder = trt.Builder(logger)
config = builder.create_builder_config()
config.max_workspace_size = workspace * 1 << 30
flag = (1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))
network = builder.create_network(flag)
parser = trt.OnnxParser(network, logger)
if not parser.parse_from_file(str(onnx)):
raise RuntimeError(f'failed to load ONNX file: {onnx}')
inputs = [network.get_input(i) for i in range(network.num_inputs)]
outputs = [network.get_output(i) for i in range(network.num_outputs)]
LOGGER.info(f'{prefix} Network Description:')
for inp in inputs:
LOGGER.info(f'{prefix}\tinput "{inp.name}" with shape {inp.shape} and dtype {inp.dtype}')
for out in outputs:
LOGGER.info(f'{prefix}\toutput "{out.name}" with shape {out.shape} and dtype {out.dtype}')
half &= builder.platform_has_fast_fp16
LOGGER.info(f'{prefix} building FP{16 if half else 32} engine in {f}')
if half:
config.set_flag(trt.BuilderFlag.FP16)
with builder.build_engine(network, config) as engine, open(f, 'wb') as t:
t.write(engine.serialize())
LOGGER.info(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
return f
except Exception as e:
LOGGER.info(f'\n{prefix} export failure: {e}')
def export_saved_model(model, im, file, dynamic,
tf_nms=False, agnostic_nms=False, topk_per_class=100, topk_all=100, iou_thres=0.45,
conf_thres=0.25, prefix=colorstr('TensorFlow SavedModel:')):
# YOLOv5 TensorFlow SavedModel export
try:
import tensorflow as tf
from tensorflow import keras
from models.tf import TFDetect, TFModel
LOGGER.info(f'\n{prefix} starting export with tensorflow {tf.__version__}...')
f = str(file).replace('.pt', '_saved_model')
batch_size, ch, *imgsz = list(im.shape) # BCHW
tf_model = TFModel(cfg=model.yaml, model=model, nc=model.nc, imgsz=imgsz)
im = tf.zeros((batch_size, *imgsz, 3)) # BHWC order for TensorFlow
y = tf_model.predict(im, tf_nms, agnostic_nms, topk_per_class, topk_all, iou_thres, conf_thres)
inputs = keras.Input(shape=(*imgsz, 3), batch_size=None if dynamic else batch_size)
outputs = tf_model.predict(inputs, tf_nms, agnostic_nms, topk_per_class, topk_all, iou_thres, conf_thres)
keras_model = keras.Model(inputs=inputs, outputs=outputs)
keras_model.trainable = False
keras_model.summary()
keras_model.save(f, save_format='tf')
LOGGER.info(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
return keras_model, f
except Exception as e:
LOGGER.info(f'\n{prefix} export failure: {e}')
return None, None
def export_pb(keras_model, im, file, prefix=colorstr('TensorFlow GraphDef:')):
# YOLOv5 TensorFlow GraphDef *.pb export https://github.com/leimao/Frozen_Graph_TensorFlow
try:
import tensorflow as tf
from tensorflow.python.framework.convert_to_constants import convert_variables_to_constants_v2
LOGGER.info(f'\n{prefix} starting export with tensorflow {tf.__version__}...')
f = file.with_suffix('.pb')
m = tf.function(lambda x: keras_model(x)) # full model
m = m.get_concrete_function(tf.TensorSpec(keras_model.inputs[0].shape, keras_model.inputs[0].dtype))
frozen_func = convert_variables_to_constants_v2(m)
frozen_func.graph.as_graph_def()
tf.io.write_graph(graph_or_graph_def=frozen_func.graph, logdir=str(f.parent), name=f.name, as_text=False)
LOGGER.info(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
return f
except Exception as e:
LOGGER.info(f'\n{prefix} export failure: {e}')
def export_tflite(keras_model, im, file, int8, data, ncalib, prefix=colorstr('TensorFlow Lite:')):
# YOLOv5 TensorFlow Lite export
try:
import tensorflow as tf
LOGGER.info(f'\n{prefix} starting export with tensorflow {tf.__version__}...')
batch_size, ch, *imgsz = list(im.shape) # BCHW
f = str(file).replace('.pt', '-fp16.tflite')
converter = tf.lite.TFLiteConverter.from_keras_model(keras_model)
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS]
converter.target_spec.supported_types = [tf.float16]
converter.optimizations = [tf.lite.Optimize.DEFAULT]
if int8:
from models.tf import representative_dataset_gen
dataset = LoadImages(check_dataset(data)['train'], img_size=imgsz, auto=False) # representative data
converter.representative_dataset = lambda: representative_dataset_gen(dataset, ncalib)
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.target_spec.supported_types = []
converter.inference_input_type = tf.uint8 # or tf.int8
converter.inference_output_type = tf.uint8 # or tf.int8
converter.experimental_new_quantizer = False
f = str(file).replace('.pt', '-int8.tflite')
tflite_model = converter.convert()
open(f, "wb").write(tflite_model)
LOGGER.info(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
return f
except Exception as e:
LOGGER.info(f'\n{prefix} export failure: {e}')
def export_edgetpu(keras_model, im, file, prefix=colorstr('Edge TPU:')):
# YOLOv5 Edge TPU export https://coral.ai/docs/edgetpu/models-intro/
try:
cmd = 'edgetpu_compiler --version'
help_url = 'https://coral.ai/docs/edgetpu/compiler/'
assert platform.system() == 'Linux', f'export only supported on Linux. See {help_url}'
if subprocess.run(cmd, shell=True).returncode != 0:
LOGGER.info(f'\n{prefix} export requires Edge TPU compiler. Attempting install from {help_url}')
for c in ['curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -',
'echo "deb https://packages.cloud.google.com/apt coral-edgetpu-stable main" | sudo tee /etc/apt/sources.list.d/coral-edgetpu.list',
'sudo apt-get update',
'sudo apt-get install edgetpu-compiler']:
subprocess.run(c, shell=True, check=True)
ver = subprocess.run(cmd, shell=True, capture_output=True, check=True).stdout.decode().split()[-1]
LOGGER.info(f'\n{prefix} starting export with Edge TPU compiler {ver}...')
f = str(file).replace('.pt', '-int8_edgetpu.tflite') # Edge TPU model
f_tfl = str(file).replace('.pt', '-int8.tflite') # TFLite model
cmd = f"edgetpu_compiler -s {f_tfl}"
subprocess.run(cmd, shell=True, check=True)
LOGGER.info(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
return f
except Exception as e:
LOGGER.info(f'\n{prefix} export failure: {e}')
def export_tfjs(keras_model, im, file, prefix=colorstr('TensorFlow.js:')):
# YOLOv5 TensorFlow.js export
try:
check_requirements(('tensorflowjs',))
import re
import tensorflowjs as tfjs
LOGGER.info(f'\n{prefix} starting export with tensorflowjs {tfjs.__version__}...')
f = str(file).replace('.pt', '_web_model') # js dir
f_pb = file.with_suffix('.pb') # *.pb path
f_json = f + '/model.json' # *.json path
cmd = f'tensorflowjs_converter --input_format=tf_frozen_model ' \
f'--output_node_names="Identity,Identity_1,Identity_2,Identity_3" {f_pb} {f}'
subprocess.run(cmd, shell=True)
json = open(f_json).read()
with open(f_json, 'w') as j: # sort JSON Identity_* in ascending order
subst = re.sub(
r'{"outputs": {"Identity.?.?": {"name": "Identity.?.?"}, '
r'"Identity.?.?": {"name": "Identity.?.?"}, '
r'"Identity.?.?": {"name": "Identity.?.?"}, '
r'"Identity.?.?": {"name": "Identity.?.?"}}}',
r'{"outputs": {"Identity": {"name": "Identity"}, '
r'"Identity_1": {"name": "Identity_1"}, '
r'"Identity_2": {"name": "Identity_2"}, '
r'"Identity_3": {"name": "Identity_3"}}}',
json)
j.write(subst)
LOGGER.info(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
return f
except Exception as e:
LOGGER.info(f'\n{prefix} export failure: {e}')
@torch.no_grad()
def run(data=ROOT / 'data/coco128.yaml', # 'dataset.yaml path'
weights=ROOT / 'yolov5s.pt', # weights path
imgsz=(640, 640), # image (height, width)
batch_size=1, # batch size
device='cpu', # cuda device, i.e. 0 or 0,1,2,3 or cpu
include=('torchscript', 'onnx'), # include formats
half=False, # FP16 half-precision export
inplace=False, # set YOLOv5 Detect() inplace=True
train=False, # model.train() mode
optimize=False, # TorchScript: optimize for mobile
int8=False, # CoreML/TF INT8 quantization
dynamic=False, # ONNX/TF: dynamic axes
simplify=False, # ONNX: simplify model
opset=12, # ONNX: opset version
verbose=False, # TensorRT: verbose log
workspace=4, # TensorRT: workspace size (GB)
nms=False, # TF: add NMS to model
agnostic_nms=False, # TF: add agnostic NMS to model
topk_per_class=100, # TF.js NMS: topk per class to keep
topk_all=100, # TF.js NMS: topk for all classes to keep
iou_thres=0.45, # TF.js NMS: IoU threshold
conf_thres=0.25 # TF.js NMS: confidence threshold
):
t = time.time()
include = [x.lower() for x in include]
tf_exports = list(x in include for x in ('saved_model', 'pb', 'tflite', 'edgetpu', 'tfjs')) # TensorFlow exports
file = Path(url2file(weights) if str(weights).startswith(('http:/', 'https:/')) else weights)
# Checks
imgsz *= 2 if len(imgsz) == 1 else 1 # expand
opset = 12 if ('openvino' in include) else opset # OpenVINO requires opset <= 12
# Load PyTorch model
device = select_device(device)
assert not (device.type == 'cpu' and half), '--half only compatible with GPU export, i.e. use --device 0'
model = attempt_load(weights, map_location=device, inplace=True, fuse=True) # load FP32 model
nc, names = model.nc, model.names # number of classes, class names
# Input
gs = int(max(model.stride)) # grid size (max stride)
imgsz = [check_img_size(x, gs) for x in imgsz] # verify img_size are gs-multiples
im = torch.zeros(batch_size, 3, *imgsz).to(device) # image size(1,3,320,192) BCHW iDetection
# Update model
if half:
im, model = im.half(), model.half() # to FP16
model.train() if train else model.eval() # training mode = no Detect() layer grid construction
for k, m in model.named_modules():
if isinstance(m, Conv): # assign export-friendly activations
if isinstance(m.act, nn.SiLU):
m.act = SiLU()
elif isinstance(m, Detect):
m.inplace = inplace
m.onnx_dynamic = dynamic
if hasattr(m, 'forward_export'):
m.forward = m.forward_export # assign custom forward (optional)
for _ in range(2):
y = model(im) # dry runs
LOGGER.info(f"\n{colorstr('PyTorch:')} starting from {file} ({file_size(file):.1f} MB)")
# Exports
f = [''] * 10 # exported filenames
if 'torchscript' in include:
f[0] = export_torchscript(model, im, file, optimize)
if 'engine' in include: # TensorRT required before ONNX
f[1] = export_engine(model, im, file, train, half, simplify, workspace, verbose)
if ('onnx' in include) or ('openvino' in include): # OpenVINO requires ONNX
f[2] = export_onnx(model, im, file, opset, train, dynamic, simplify)
if 'openvino' in include:
f[3] = export_openvino(model, im, file)
if 'coreml' in include:
_, f[4] = export_coreml(model, im, file)
# TensorFlow Exports
if any(tf_exports):
pb, tflite, edgetpu, tfjs = tf_exports[1:]
if int8 or edgetpu: # TFLite --int8 bug https://github.com/ultralytics/yolov5/issues/5707
check_requirements(('flatbuffers==1.12',)) # required before `import tensorflow`
assert not (tflite and tfjs), 'TFLite and TF.js models must be exported separately, please pass only one type.'
model, f[5] = export_saved_model(model, im, file, dynamic, tf_nms=nms or agnostic_nms or tfjs,
agnostic_nms=agnostic_nms or tfjs, topk_per_class=topk_per_class,
topk_all=topk_all, conf_thres=conf_thres, iou_thres=iou_thres) # keras model
if pb or tfjs: # pb prerequisite to tfjs
f[6] = export_pb(model, im, file)
if tflite or edgetpu:
f[7] = export_tflite(model, im, file, int8=int8 or edgetpu, data=data, ncalib=100)
if edgetpu:
f[8] = export_edgetpu(model, im, file)
if tfjs:
f[9] = export_tfjs(model, im, file)
# Finish
f = [str(x) for x in f if x] # filter out '' and None
LOGGER.info(f'\nExport complete ({time.time() - t:.2f}s)'
f"\nResults saved to {colorstr('bold', file.parent.resolve())}"
f"\nVisualize with https://netron.app"
f"\nDetect with `python detect.py --weights {f[-1]}`"
f" or `model = torch.hub.load('ultralytics/yolov5', 'custom', '{f[-1]}')"
f"\nValidate with `python val.py --weights {f[-1]}`")
return f # return list of exported files/dirs
def parse_opt():
parser = argparse.ArgumentParser()
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model.pt path(s)')
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640, 640], help='image (h, w)')
parser.add_argument('--batch-size', type=int, default=1, help='batch size')
parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--half', action='store_true', help='FP16 half-precision export')
parser.add_argument('--inplace', action='store_true', help='set YOLOv5 Detect() inplace=True')
parser.add_argument('--train', action='store_true', help='model.train() mode')
parser.add_argument('--optimize', action='store_true', help='TorchScript: optimize for mobile')
parser.add_argument('--int8', action='store_true', help='CoreML/TF INT8 quantization')
parser.add_argument('--dynamic', action='store_true', help='ONNX/TF: dynamic axes')
parser.add_argument('--simplify', action='store_true', help='ONNX: simplify model')
parser.add_argument('--opset', type=int, default=12, help='ONNX: opset version')
parser.add_argument('--verbose', action='store_true', help='TensorRT: verbose log')
parser.add_argument('--workspace', type=int, default=4, help='TensorRT: workspace size (GB)')
parser.add_argument('--nms', action='store_true', help='TF: add NMS to model')
parser.add_argument('--agnostic-nms', action='store_true', help='TF: add agnostic NMS to model')
parser.add_argument('--topk-per-class', type=int, default=100, help='TF.js NMS: topk per class to keep')
parser.add_argument('--topk-all', type=int, default=100, help='TF.js NMS: topk for all classes to keep')
parser.add_argument('--iou-thres', type=float, default=0.45, help='TF.js NMS: IoU threshold')
parser.add_argument('--conf-thres', type=float, default=0.25, help='TF.js NMS: confidence threshold')
parser.add_argument('--include', nargs='+',
default=['torchscript', 'onnx'],
help='torchscript, onnx, openvino, engine, coreml, saved_model, pb, tflite, edgetpu, tfjs')
opt = parser.parse_args()
print_args(FILE.stem, opt)
return opt
def main(opt):
for opt.weights in (opt.weights if isinstance(opt.weights, list) else [opt.weights]):
run(**vars(opt))
if __name__ == "__main__":
opt = parse_opt()
main(opt)
安装简化器,如果出错则需要先更新cmake,因此我们建议以上简化过程最好在PC下Ubuntu虚拟机完成而不是在JetsonNano中:
CMake Error at CMakeLists.txt:21 (cmake_minimum_required): CMake 3.13 or higher is required. You are running version 3.10.2 -- Configuring incomplete, errors occurred!更新cmake:
git clone https://github.com/Kitware/CMake
./bootstrap.sh
make
sudo make install
cmake --version更新gcc,g++:
sudo apt-get install gcc-8
sudo apt-get install g++-8配置为默认启动:
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-8 100
sudo update-alternatives --config gcc
sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-8 100
sudo update-alternatives --config g++安装简化器:
pip3 install onnx-simplifier
优化模型:
python3 -m onnxsim ./yolov5s.onnx ./sim_yolov5s.onnx最终新建如下脚本,修改对应文件名和输出路径后在JetsonNano上运行,将优化后的onnx导出为engine,之后再yolov5中调用方式与之前一样:
import tensorrt as trt
import sys
import os
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
EXPLICIT_BATCH = 1 << (int)(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)
def printShape(engine):
for i in range(engine.num_bindings):
if engine.binding_is_input(i):
print("input layer: {}, shape is: {} ".format(i, engine.get_binding_shape(i)))
else:
print("output layer: {} shape is: {} ".format(i, engine.get_binding_shape(i)))
def onnx2trt(onnx_path, engine_path):
with trt.Builder(TRT_LOGGER) as builder, builder.create_network(EXPLICIT_BATCH) as network, trt.OnnxParser(network, TRT_LOGGER) as parser:
builder.max_workspace_size = 1 << 28 # 256MB
with open(onnx_path, 'rb') as model:
parser.parse(model.read())
engine = builder.build_cuda_engine(network)
printShape(engine)
with open(engine_path, "wb") as f:
f.write(engine.serialize())
if __name__ == "__main__":
input_path = "./sim_yolov5s.onnx"
output_path = input_path.replace('.onnx', '.engine')
onnx2trt(input_path, output_path)
注:目前采用该方法导出后,可能是相关参数配置有问题,相比方法1速度慢很多,如果有了解的人可以在QQ群解答!

