
1. 应用测试
首先完成Rviz插件的安装其可以显示机器人相关Box或规划路径等插件和msg消息,使用其完成对检测后Box发布:
sudo apt-get install ros-melodic-jsk-recognition-msgs
sudo apt-get install ros-melodic-jsk-rviz-plugins之后运行所有的导航节点,运行加速的识别项目,则再识别后将在相机坐标系发布相应的识别结果,我们最终选择map作为显示坐标系,则Box将在全局地图中进行显示。
roslaunch robot_vslam camera.launch
roslaunch robot_navigation robot_lidar.launch
roslaunch robot_navigation cartographer.launch
roslaunch yolov5_ros yolo_v5f.launch
roslaunch robot_vslam move_base.launch planner:=teb move_forward_only:=false
roslaunch robot_navigation multi_navigation.launch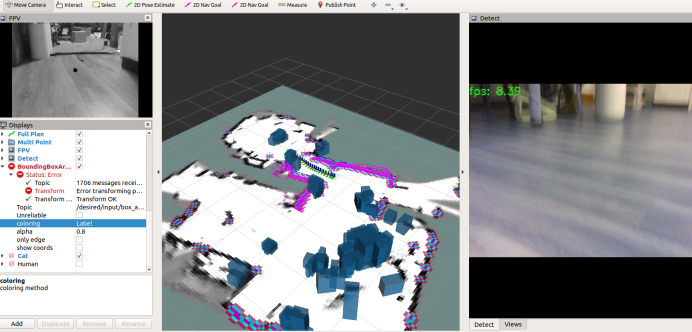
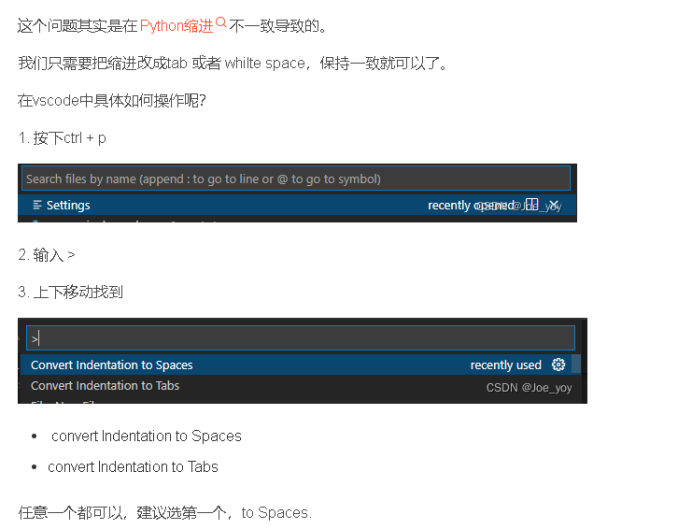
注:在编辑python脚本时如果遇到Inconsistent use of tabs and spaces in indentation该怎么办?
2. 原理说明
本文使用的标记方式非常简单,首先通过YoloV5可以完成对图像中目标的识别,绘制出其方框,这样我们就知道了一个物体在图像坐标系下的中心点和尺寸,由于我们知道相机的内参,因此可以将其进一步换算到光心坐标系下得到其标准尺度下的位置:
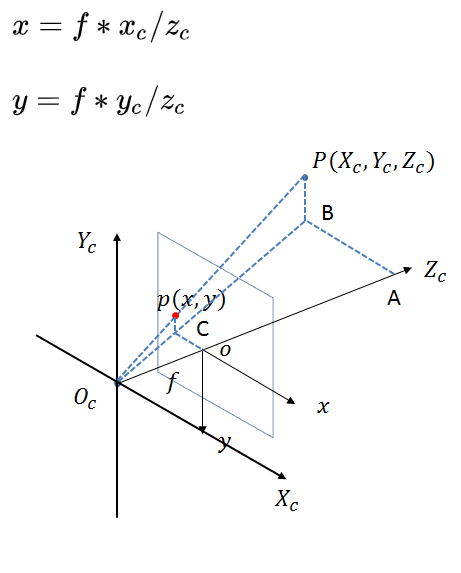
则如果我们知道相机的内参和当前该点的物理深度zc就可以得到相机坐标系下该像素点的具体位置。
对于前者我们使用的是RealsenseD435在启动其ROS节点后会自动发布相机的camera_info,我们只需要订阅就可以获取到其焦距和光心位置:
def color_camera_info_callback(self, data):
self.rgb_height = data.height
self.rgb_width = data.width
# Pixels coordinates of the principal point (center of projection)
self.rgb_u = data.P[2]
self.rgb_v = data.P[6]
# Focal Length of image (multiple of pixel width and height)
self.rgb_fx = data.P[0]
self.rgb_fy = data.P[5]则基于上面的公式我们可以得到如下等式:
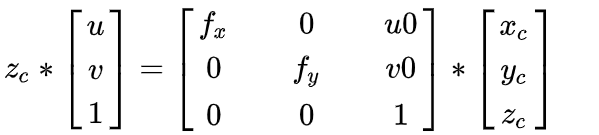
上图中只要知道了zc就可以求取相机坐标系下像素点位置xc,yc,zc,则我们可以采用当前RealSense的深度图来获取,我们订阅深度与RGB对齐的图像/camera/aligned_depth_to_color/image_raw,则采用识别中性点获取深度值完成像素点位置的求解,这里需要注意的是当前仅读取了识别框中性点的深度,但在实际使用中很可能优于反光这里没有值,因此理论上可以多读取甚至读取整个识别框内深度求平均,但这样在python接口下会非常占用时间:
def transformation(self,top_left_x, top_left_y, bottom_right_x, bottom_right_y, center_x, center_y):
cube_w=2
cube_h=2
size=cube_h*cube_w
distance_z=0
num=0
if 0:
for ys in range(int(center_y)-int(cube_h/2),int(center_y)+int(cube_h/2)):
for xs in range(int(center_x)-int(cube_w/2),int(center_x)+int(cube_w/2)):
if ys>0 and ys<480 and xs>0 and xs<640:
temp=self.depth_array[ys,xs][0]
if temp>0.1 and temp<1.8:
distance_z=distance_z+temp
num=num+1
if num>0:
distance_z = distance_z/num
else:
temp=self.depth_array[center_y,center_x][0]
if temp>0.1 and temp<1.8:
distance_z=temp
if center_x>=640:
center_x=480
elif center_x<=0:
center_x=0
expected_3d_center_distance = distance_z
expected_3d_top_left_x = ((top_left_x - self.rgb_u)*distance_z)/self.rgb_fx
expected_3d_top_left_y = ((top_left_y - self.rgb_v)*distance_z)/self.rgb_fy
expected_3d_bottom_right_x = ((bottom_right_x - self.rgb_u)*distance_z)/self.rgb_fx
expected_3d_bottom_right_y = ((bottom_right_y - self.rgb_v)*distance_z)/self.rgb_fy
expected_3d_center_x = ((center_x - self.rgb_u)*distance_z)/self.rgb_fx
expected_3d_center_y = ((center_y - self.rgb_v)*distance_z)/self.rgb_fy
good_depth=1
if distance_z==0:
good_depth=0
return good_depth,expected_3d_center_distance,expected_3d_center_x,expected_3d_center_y, expected_3d_top_left_x, expected_3d_top_left_y, expected_3d_bottom_right_x, expected_3d_bottom_right_y
上面的代码即将像素点转换为物理位置,由于我们仅能检测识别框因此对其4个顶点做同样的处理,最终得到其在空间中的位置和方框大小。
最终,采用Box消息将其发布,并在Rviz中进行绘制,由于我们得到的是相机坐标系下的位置,因此其x为左右,y为上下,z为目标深度:
box.header.stamp = rospy.Time.now()
box.header.frame_id = camera_frame_name
box.pose.orientation.w = 1.0
box.pose.position.x = (box_position_x) #increase in program = move to right in rviz
box.pose.position.y = -box_size_y/2 #gaodu move to map top face (box_position_y) # increase in program = downward in rviz
box.pose.position.z = (box_position_z)+base_camera_off #shendu increase in program = move away in rviz (directly use the depth distance)
box.dimensions.x = (box_size_x)
box.dimensions.y = (box_size_y)
box.dimensions.z = (box_size_z)
box.label=int(yolov5_wrapper.result_classid[i])
box.value=0上述Box在发布后会显示在MAP中,而我们要用于后续计算,需要进一步求取该目标在MAP坐标系下的位置,通过订阅里程计信息,进行位置变换即可得到:
yaw=-detection.odom_yaw
x_bn= box.pose.position.z*math.cos(yaw)-box.pose.position.x*math.sin(yaw)
y_bn=-box.pose.position.x*math.cos(yaw)-box.pose.position.z*math.sin(yaw)
x_n=detection.odom_x+x_bn
y_n=detection.odom_y+y_bn那最后知道了一个特点目标在MAP中的位置测量结果,可以直接发布导航点,让机器人运动过去:
goalMsg = PoseStamped()
goalMsg.header.frame_id = "odom"
goalMsg.pose.orientation.z = 0.0
goalMsg.pose.orientation.w = 1.0
goalMsg.header.stamp = rospy.Time.now()
goalMsg.pose.position.x = x_n
goalMsg.pose.position.y = y_n
goalMsg.pose.orientation.x = 0.0
goalMsg.pose.orientation.y = 0.0
goalMsg.pose.orientation.z = 0.0
goalMsg.pose.orientation.w = 1.0
detection.pub_goal.publish(goalMsg) 注:上面仅完成了对目标位置的检测和测量,对于真正应用可以增加对目标位置的运动估计,或者采用KCF跟踪算法提高识别帧率!

