
2024年6月1日 星期三 我正式开始了学习RL,本教程总共分为5篇内容
实际在博士期间最早课题是想开强化学习,但由于当时导师和实验室并没有相关资源最后还是选择了数据融合方向,也完整的学习莫凡Python的RL和相关课程,并且实现了基于DQN驱动2D仿真中无人机完成自动避障和探索的任务,因此有过对马尔科夫过程Q学习和后续深度强化学习基本知识的理解。
在后续某科研项目中涉及到了需要让智能体学习一个策略实现对步态模式、控制参数基于算力和环境、地形复杂度实现自演化的要求,因此最后还是采用了Q学习+RBF网络拟合的方式实现对连续环境特征输入到输出离散动作组指令的强化学习模型编程,算是再次捡起了基本的内容,下面是近期针对强化学习开展学习的记录,里面并不涉及强化学习算法、模型网络设计等基础神经网络和RL知识,更多是从工程层面实现快速上手应用Isacc仿真环境并实现Sim2Sim迁移的过程,可以快速了解采用强化学习这种控制方法实现系统设计的基础流程,项目参考了很多开源项目,这也是目前学习强化学习的最大好处有越来越多的教程。
为了更好的学习强化学习,整个过程从3D模型构建、URDF导出、ROS校验、Isacc训练和Mojoco迁移完成了整个流程的记录,并且采用了Tinymal四足机器人模型为例进行测试,更深度的实现一个新机器人完整的训练过程,从不了解Isacc到完成Mujoco迁移整个过程和时间排列如下:
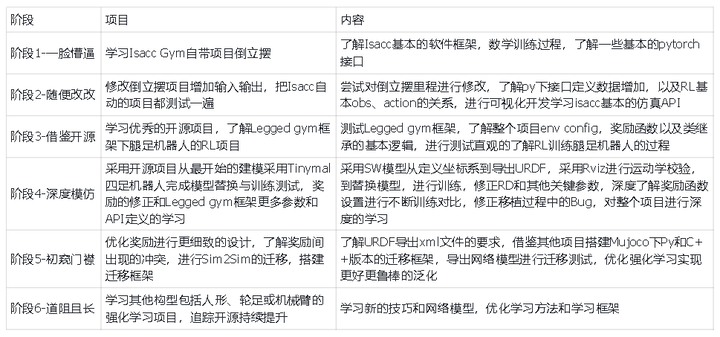
添加图片注释,不超过 140 字(可选)通过整个过程的学习可以基本了解Isacc Gym的使用,并且可以用自己的机器人模型进行测试,当然很多更深层次的细节和RL知识需要更深入的学习,但是起码了解了RL的基本流程并且可以针对很多开源项目进行学习,随着Isacc Lab和Sim的推出,Gym不再做更新维护,未来强化学习的工具链会更加丰富,具身智能系统的开发会变得更加的方便, 当然这也完成了对Tinymal项目整个框架中缺失部分的填充:

Tinymal项目宇宙补完RL强化学习部分,RL从0到1手把手全流程如下
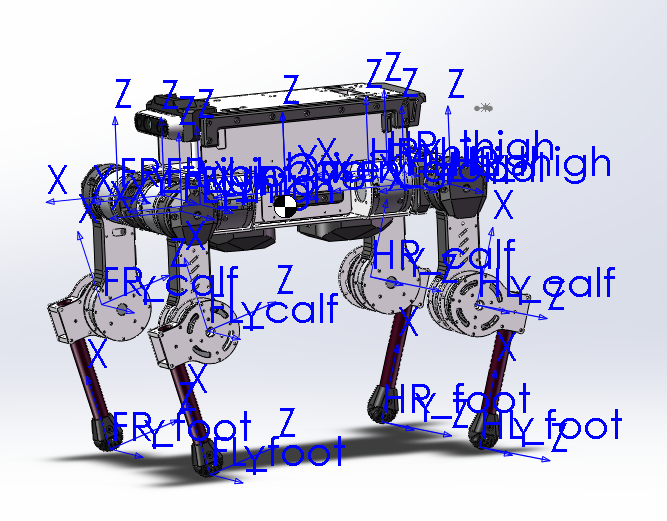
【1】机器人建模和导出

【2】Isaac强化学习

【3】Mujoco Sim2Sim

【4】零样本实物样机迁移实物样机部署,测试部署结果:

样机部署测试
阶段1 学习IsaccGymEnv 倒立摆例子
在学习的一开始首先是学习如何安装Isacc Gym所需要的依赖环境,并且开始对基础的例子进行学习,对于传统控制学习来说倒立摆是最典型的例子,其从系统建模和控制都是传统控制课程首选的代表,对于RL学习也一样,下面为修改后的gym例子:
链接: https://pan.baidu.com/s/16_pRDKUhail8IivIIlB44A?pwd=fs5y 提取码: fs5y 复制这段内容后打开百度网盘手机App,操作更方便哦
https://github.com/isaac-sim/IsaacGymEnvs/blob/main/docs/rl_examples.mdgithub.com/isaac-sim/IsaacGymEnvs/blob/main/docs/rl_examples.md
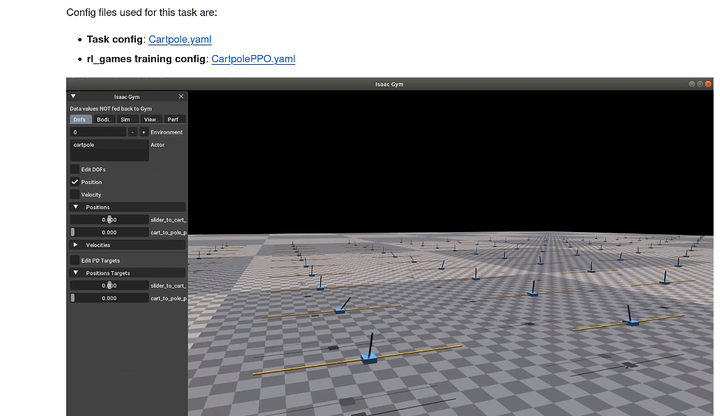
)在IsaccGymEnvs中提供了非常多的RL例子包括倒立摆、机械臂和人形,可以快速了解并且直观的学习Isacc仿真环境。
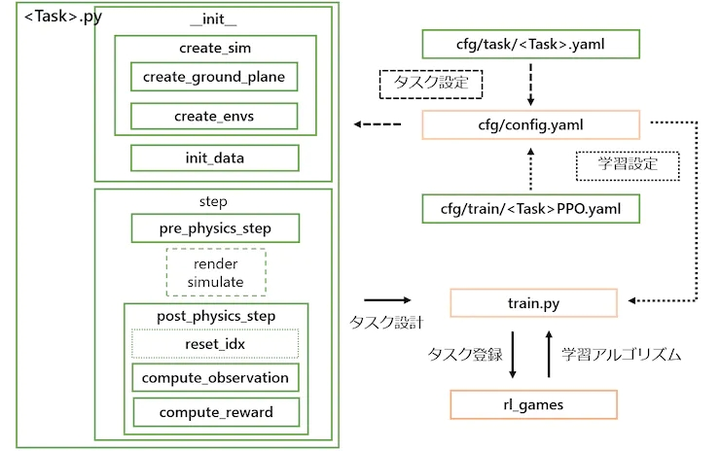
Gym的RL基本软件框架
激活虚拟空间:
conda activate HITtrain:训练脚本
python train.py task=CartpoleLoad per-train:
python train.py task=Ant checkpoint=runs/Ant/nn/Ant.pth通过运行例程,首先可以了解train脚本的参数输入:
train.py 文件描述
- device_typethe type of device used for simulation. cuda or cpu.
- device_idID of the device used for simulation. eg 0 for a single GPU workstation.
- rl_deviceFull name:id string of the device that the RL framework is using.
headless - True/False depending on whether you want the simulation to run the simulation with a viewer.
- physics_enginewhich physics engine to use. Must be "physx" or "flex".
- enva dictionary with environment-specific parameters. Can include anything in here you want depending on the specific parameters, but key ones which you must provide are:
- numEnvsnumber of environments being simulated in parallel
- numObservationssize of the observation vector used for each environment.
- numActionssize of the actions vector.
同时,了解基本的RL框架包括环境参数和强化学习参数:
训练环境包括了环境数量,输入输出维度定义等参数,参数配置env文件yaml为:
/home/pi/Downloads/humanplus-main/IsaacGymEnvs-main/isaacgymenvs/cfg/task/Cartpole.yaml
强化学习目前一般采用PPO训练方法,其参数yaml为:
/home/pi/Downloads/humanplus-main/IsaacGymEnvs-main/isaacgymenvs/cfg/train/CartpolePPO.yaml
同时了解了对于一个新RL工程如何建议并注册在Task参数中,新建任务在:
/home/pi/Downloads/humanplus-main/IsaacGymEnvs-main/isaacgymenvs/tasks/__init__.py
# Mappings from strings to environments
isaacgym_task_map = {
"AllegroHand": AllegroHand,
"AllegroKuka": resolve_allegro_kuka,
"AllegroKukaTwoArms": resolve_allegro_kuka_two_arms,
"AllegroHandManualDR": AllegroHandDextremeManualDR,
"AllegroHandADR": AllegroHandDextremeADR,
"Ant": Ant,
"Anymal": Anymal,
"AnymalTerrain": AnymalTerrain,
"BallBalance": BallBalance,
"Cartpole": Cartpole,
"FactoryTaskGears": FactoryTaskGears,
"FactoryTaskInsertion": FactoryTaskInsertion,
"FactoryTaskNutBoltPick": FactoryTaskNutBoltPick,
"FactoryTaskNutBoltPlace": FactoryTaskNutBoltPlace,
"FactoryTaskNutBoltScrew": FactoryTaskNutBoltScrew,
"IndustRealTaskPegsInsert": IndustRealTaskPegsInsert,
"IndustRealTaskGearsInsert": IndustRealTaskGearsInsert,
"FrankaCabinet": FrankaCabinet,
"FrankaCubeStack": FrankaCubeStack,
"Humanoid": Humanoid,
"HumanoidAMP": HumanoidAMP,
"Ingenuity": Ingenuity,
"Quadcopter": Quadcopter,
"ShadowHand": ShadowHand,
"Trifinger": Trifinger,
} 新任务建立后,同时需要在task目录下新增earning和task对应名称后缀的yaml文件!
了解了项目框架下机器人模型一般放置在asset目录下:
/home/pi/Downloads/humanplus-main/IsaacGymEnvs-main/assets/urdf/cartpole.urdf对于一个RL项目整体框架代码流程如下:
def create_sim(self):
# implement sim set up and environment creation here
# - set up-axis
# - call super().create_sim with device args (see docstring)
# - create ground plane
# - set up environments
#pre_physics_step:在执行仿真前需要计算的内容,比如智能体的动作计算。我们在这里设置了目标agent受到3个坐标系方向的推力,并且每次增加的是推力的变化量,同时对最大推力进行了限幅。
def pre_physics_step(self, actions):#前处理完成期望和绕道增加
# implement pre-physics simulation code here
# - e.g. apply actions
def post_physics_step(self):#后处理完成观测和奖励更新
# implement post-physics simulation code here
# - e.g. compute reward, compute observations原始项目中通过reset_buf标志位来判断哪个环境复位,复位条件一般为到达复位摔倒状态或者满足这次回合训练次数:
# adjust reward for reset agents 复位奖励
reward = torch.where(torch.abs(cart_pos) > reset_dist, torch.ones_like(reward) * -2.0, reward)#小车位置超出偏差给负数奖励
reward = torch.where(torch.abs(pole_angle) > np.pi / 2, torch.ones_like(reward) * -2.0, reward)#倒立摆摔倒 给负奖励
reset = torch.where(torch.abs(cart_pos) > reset_dist, torch.ones_like(reset_buf), reset_buf) #当达到前面条件 reset_buf进行赋值
reset = torch.where(torch.abs(pole_angle) > np.pi / 2, torch.ones_like(reset_buf), reset)
reset = torch.where(progress_buf >= max_episode_length - 1, torch.ones_like(reset_buf), reset)因此在post后处理时会实时检测那个reset_buf为1,则对其复位:
def post_physics_step(self):
self.progress_buf += 1
self.gym.refresh_actor_root_state_tensor(self.sim)#刷新tensor相关数据
self.gym.refresh_net_contact_force_tensor(self.sim)
self.gym.refresh_rigid_body_state_tensor(self.sim)
env_ids = self.reset_buf.nonzero(as_tuple=False).squeeze(-1)
if len(env_ids) > 0:#检测满足复位标志位1的环境ID
self.reset_idx(env_ids)另外是一些常规的配置:
(1)设置最大训练步骤在PPO.yaml中:
score_to_win: 20000
max_epochs: ${resolve_default:10000,${....max_iterations}}(2)设置训练环境参数如个数、控制范围等,在env的yaml中:
env:
numEnvs: ${resolve_default:512,${...num_envs}}
envSpacing: 4.0 #空间尺寸
resetDist: 3.0 #小车位置复位判断
maxEffort: 400.0 #最大控制量扭矩
clipObservations: 5.0
clipActions: 1.0
randomCommandPosRanges: 1 #控制范围在运行项目的过程中了解到Gym API和tensor相关用法:
refresh_dof_state_tensor 此函数将使用物理引擎的最新值填充张量。从这个张量创建的所有视图或切片都将自动更新
Sim: “Sim”是指模拟器(simulator),是仿真的核心组件。它负责处理物理计算和仿真的所有细节,如动力学、碰撞检测和其他物理交互。Isaac Gym使用NVIDIA PhysX作为其后端物理引擎,可以高效地在GPU上运行。在代码中的体现是,调用sim可以完成对模拟器的step。
Env: “Env”是指环境(environment),是智能体(agent)进行学习和互动的场所。每个环境包含了特定的任务或场景设置,智能体需要在这些环境中执行操作以获取奖励并学习策略。
Actor: “Actor”是在仿真中表示具有物理属性的对象,如机器人、物体等。每个Actor包括了用于描述其形状、质量、动力学属性等的各种参数。Actors是智能体与环境互动的主体,例如一个机器人的手臂或车辆。
Rigid: “Rigid”,刚体,是一种物理对象,其形状在仿真过程中不会发生变化。在Isaac Gym中,刚体用来表示那些不需要弹性或变形特性的实体。刚体动力学是计算这些对象如何在力和碰撞作用下移动和反应的基础。
Index / indcies: 这是一个很容易混淆的概念,特别是在多env多actor,每个actor拥有1个以上rigid时。理解index的索引获取和它代表的对象非常重要。举例在倒立摆例子中读取观测:
def compute_observations(self, env_ids=None):
if env_ids is None:
env_ids = np.arange(self.num_envs)
self.gym.refresh_dof_state_tensor(self.sim) #从仿真器获取数据
self.obs_buf[env_ids, 0] = self.dof_pos[env_ids, 0].squeeze()
self.obs_buf[env_ids, 1] = self.dof_vel[env_ids, 0].squeeze()
self.obs_buf[env_ids, 2] = self.dof_pos[env_ids, 1].squeeze()
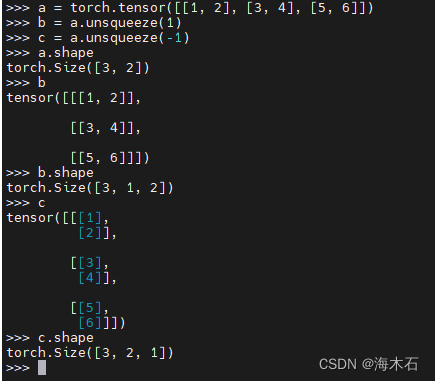
self.obs_buf[env_ids, 3] = self.dof_vel[env_ids, 1].squeeze().squeeze()方法语法
numpy.squeeze(a, axis=None)其中,参数a是需要操作的数组,axis是要删除的维度。若不指定axis参数,则squeeze()方法会删除所有长度为1的维度,主要功能时降维排列:
torch.where()常规用法
torch.where(condition, x, y)
根据条件,也就是condiction,返回从x或y中选择的元素的张量(这里会创建一个新的张量,新张量的元素就是从x或y中选的,形状要符合x和y的广播条件)。
Parameters解释如下:
1、condition (bool型张量) :当condition为真,返回x的值,否则返回y的值
2、x (张量或标量):当condition=True时选x的值
2、y (张量或标量):当condition=False时选y的值

添加图片注释,不超过 140 字(可选)API说明:
(API介绍在isaacgym/docs/api/python/gym_py.html这个文件中,用浏览器打开这个文件查看即可。)
1) isaacgym.gymapi.Gym.acquire_actor_root_state_tensor()
检索Actor root states缓冲区,包含位置[0:3], 旋转[3:7], 线速度[7:10], 角速度[10:13]
isaacgym.gymapi.Gym.refresh_actor_root_state_tensor()
更新actor root state缓冲区
2) saacgym.gymapi.Gym.acquire_dof_state_tensor()
检索DoF state缓冲区,维度为(num_dofs,2), 每一个dof state包含位置和速度
isaacgym.gymapi.Gym.refresh_dof_state_tensor()
更新DOF state缓冲区
3) isaacgym.gymapi.Gym.acquire_net_contact_force_tensor()
检索net contact forces缓冲区,维度为(num_rigid_bodies,3), 每个接触力状态包含x,y,z轴的一个值。
isaacgym.gymapi.Gym.refresh_net_contact_force_tensor()
更新net contact forces缓冲区
4) isaacgym.gymapi.Gym.acquire_rigid_body_state_tensor()
检索rigid body states缓冲区,维度为(num_rigid_bodies,13), 每个刚体的状态包含位置[0:3], 旋转[3:7], 线速度[7:10], 角速度[10:13]
isaacgym.gymapi.Gym.refresh_rigid_body_state_tensor()
更新rigid body state缓冲区
5) saacgym.gymapi.Gym.acquire_force_sensor_tensor()
检索force sensors缓冲区,维度为(num_force_sensor, 6),每个力传感器状态包含3维力,3维力矩。
isaacgym.gymapi.Gym.refresh_force_sensor_tensor
更新force sensors缓冲区
问张量的内容,可以使用:
root_tensor = gymtorch.wrap_tensor(_root_tensor)强化学习模型复位,在计算奖励时候进行判断采用where进行赋值
reset = torch.where(torch.abs(cart_pos) > reset_dist, torch.ones_like(reset_buf), reset_buf) #当达到前面条件 reset_buf进行赋值 为1的张量在判断某个环境满足为1条件时进行复位:
env_ids = self.reset_buf.nonzero(as_tuple=False).squeeze(-1)
if len(env_ids) > 0:
self.reset_idx(env_ids)倒立摆增加控制指令:
self.command_pos_range = self.cfg["env"]["randomCommandPosRanges"]
self.commands = torch.zeros(self.num_envs, 1, dtype=torch.float, device=self.device, requires_grad=False)#增加控制指令在奖励增加新的变量需要定义接口变量类型:
# type: (Tensor,Tensor, Tensor, Tensor, Tensor, float, Tensor, Tensor, float) -> Tuple[Tensor, Tensor]参考isaac gym的例程franka_ cube_ik_osc.py其中,涉及使用函数:
gym.get_actor_rigid_body_index,DOMAIN_SIM表示返回sim中的句柄,DOMAIN_ENV则是返回env中的句柄。
box_idx = gym.get_actor_rigid_body_index(env, box_handle, 0, gymapi.DOMAIN_SIM)
box_idxs.append(box_idx) gym.find_actor_rigid_body_handle,查找给定名称的actor刚体句柄。
hand_handle = gym.find_actor_rigid_body_handle(env, franka_handle, "panda_hand")
hand_pose = gym.get_rigid_transform(env, hand_handle)
gym.find_actor_rigid_body_index,使用此函数可查找状态缓冲区中刚体的索引。
hand_idx = gym.find_actor_rigid_body_index(env, franka_handle, "panda_hand", gymapi.DOMAIN_SIM)
hand_idxs.append(hand_idx)以上带有DOMAIN_SIM一类参数函数是部分查找函数的集合,所以有更多不同名称的调用方法,具体见handbook。
获取index后即可切片读取信息:
box_pos = rb_states[box_idxs, :3]
box_rot = rb_states[box_idxs, 3:7]
hand_pos = rb_states[hand_idxs, :3]
hand_rot = rb_states[hand_idxs, 3:7]
hand_vel = rb_states[hand_idxs, 7:]总结
下一小节将介绍阶段2修改倒立摆例子并学习IsaccGymEnv其他项目,欢迎大家关注,后续会推出B站视频教程!

