
1. 硬件设备搭建与基本功能测试
首先购买微雪的语音交互模组

推荐
为了提高识别率建议购买外置麦克风:

如果不想插入多个不同设备也可以单独购买一体化的模块:

推荐
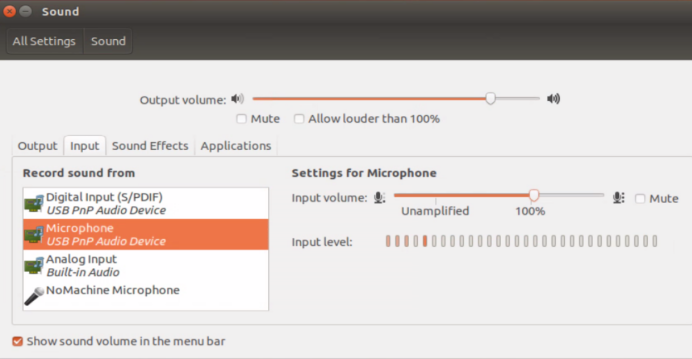
将上述设备接入JetsonNano后,首先需要通过nomachine打开音响配置然后选择默认的声卡input和output,增加输入输出音量,测试是否有声音:
参考微雪官网例程完成依赖的安装:

之后就可以完成对微雪自带例程的测试。
2. ChatGPT3测试
联网说明
这俩采用网上开源的例子进行修改,测试ChatGPT3基本的语音交互功能,由于原始版本基于树莓派,这俩我按照JetsonNano的配置进行了修改,下载地址为:
链接:https://pan.baidu.com/s/1l3Jl2eh3RRU4JQ2aFl1jfQ
提取码:wqtp
--来自百度网盘超级会员V3的分享首先需要注册百度AI账号,开启语音识别功能,可以通过免费领取语音识别次数,或者花费1元进行购买:

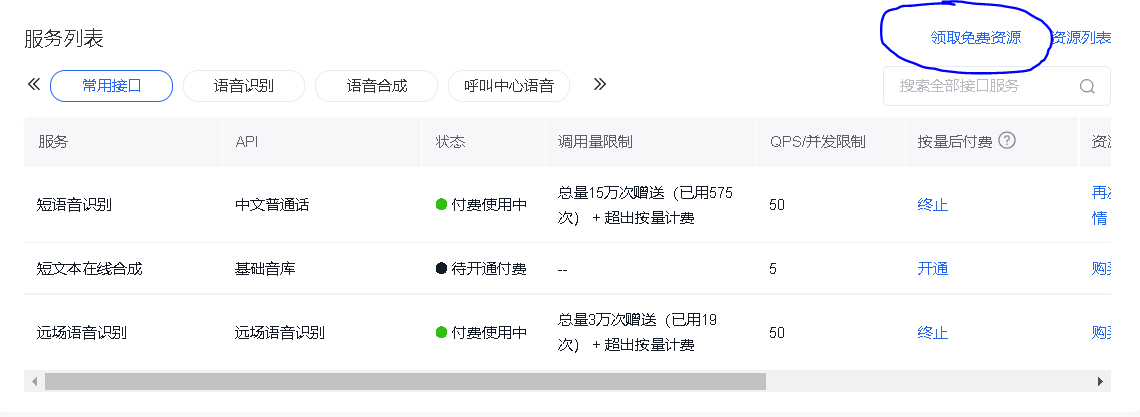
创建一个新的应用,将对应ID、Key复制到config文件中:


main.py中首先采用pvporcupine作为唤醒词识别:
porcupine = pvporcupine.create(access_key = Picovoice_key,keywords=['ok google','terminator'],sensitivities=[0.6,0.9])同样需要注册https://picovoice.ai/ ,这样也方便后续训练自己声音的唤醒词:
Picovoice_key="GwOdbPXDu/Sewyx19hrj+oL+U6jvvK7ixgVPNK2YEK2Z3rMhyVUxAA=="
Picovoice_keyword_paths=[r'data/picovoice/shell-ball_en_windows_v2_1_0.ppn']
然后使用TTS完成后续ChatGPT得到文字转语音播报:
wsParam = Ws_Param(APPID='58e61263', APISecret='dffb2043eeb3624eff11f4df0fd84d7d',
APIKey='36d5946d3501388b423ce66f633385f9',
Text="Tinymal Video Checker On")
websocket.enableTrace(False)
wsUrl = wsParam.create_url()
ws = websocket.WebSocketApp(wsUrl, on_message=on_message, on_error=on_error, on_close=on_close)则在完成上述设置后如果依赖安装无误,运行main文件即出现Tinymal的欢迎词:
在说出['ok google','terminator']固定唤醒词后,如果连续输入一段对话,则会自动发生给ChatGPT3,获取答案后进行播报:

